Serien-Navigation · MCP im Enterprise
Teil 1 (aktuell) · Teil 2 (in Arbeit) · Teil 3 (in Arbeit)
Serie: MCP im Enterprise-Betrieb (Teil 1 von 3)
Viele Teams haben MCP zunächst als „spannendes Dev-Thema“ behandelt: schnell mal einen Server anbinden, ein paar Tools exposen, Demo bauen. Das funktioniert für erste Experimente gut. Im Enterprise kippt die Frage aber schnell von „Können wir das?“ zu „Können wir das stabil, sicher und steuerbar betreiben?“. Genau an diesem Punkt wird aus Hype Infrastruktur.
Der aktuelle Shift ist deshalb wichtig: MCP wird nicht mehr nur als Bastel-Interface wahrgenommen, sondern als Integrationsschicht, die in reale Teams, Prozesse und Governance passen muss. Und das hat direkte Folgen für Architektur, Security und Ownership.
Was sich gerade im Marktbild ändert
- Ökosystem-Reife: MCP taucht zunehmend in Programmen und Events auf, die klar auf produktive Nutzung zielen.
- Konkrete Use Cases: Statt reiner „AI kann Tool X aufrufen“-Demos sieht man mehr End-to-End-Szenarien mit echten Workflows.
- Betriebsfokus: Themen wie Registry, Versionierung, Freigaben und Audits werden wichtiger als reine Feature-Listen.
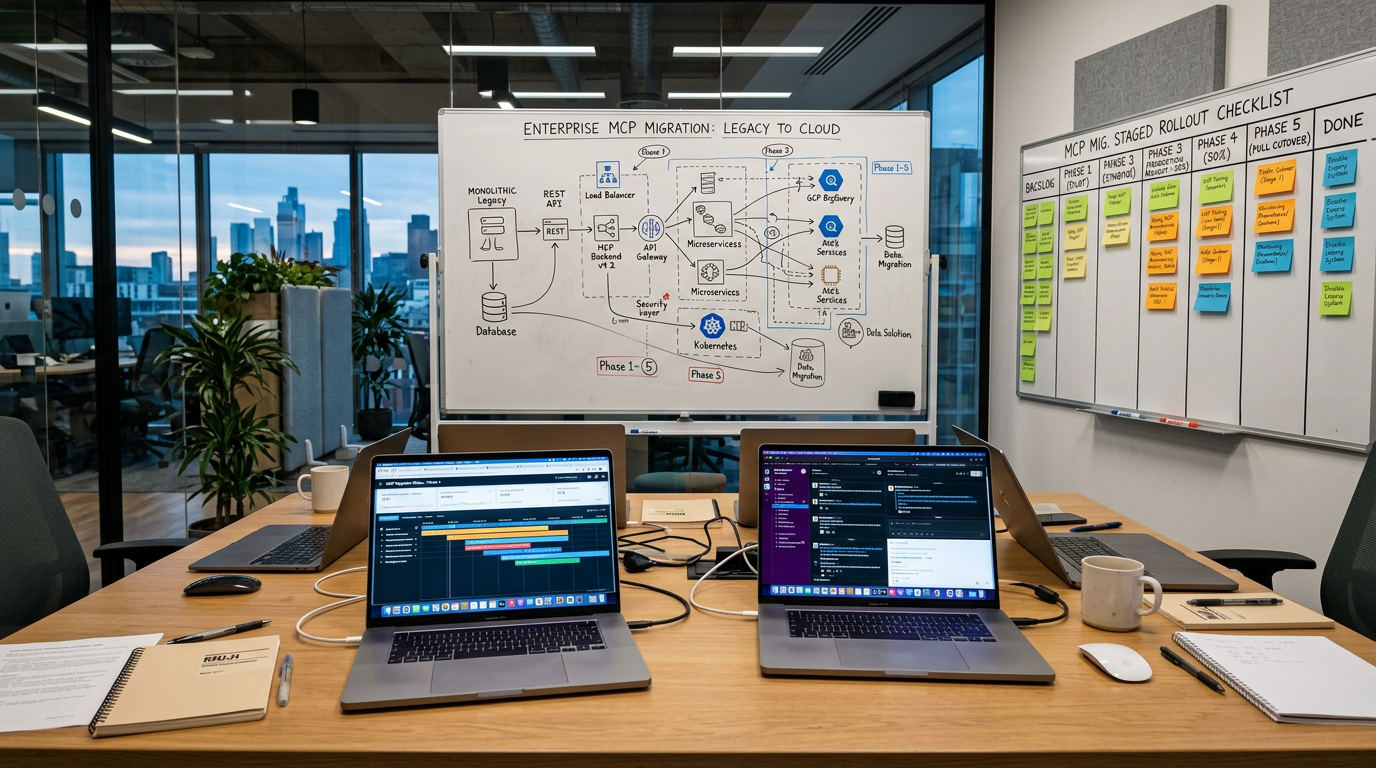
Die drei Architekturfragen, die früh geklärt werden müssen
1) Wer kontrolliert den Zugriff?
Ohne sauberes Scope- und Rechtekonzept wird MCP schnell zum Schatten-Integrationslayer. Teams brauchen klare Regeln: Welche Server sind erlaubt? Welche Aktionen sind read-only? Wo ist Human-in-the-loop Pflicht?
2) Wie versionieren wir MCP-Server?
Unklare Server-Versionen führen bei Agent-Flows sehr schnell zu instabilem Verhalten. Stabiler Betrieb heißt: definierte Versionen, kontrollierte Rollouts, Rollback-Fähigkeit.
3) Was ist unser Erfolgsmaß?
MCP sollte nicht „cool“ sein, sondern Nutzen liefern. Typische Kennzahlen: Durchlaufzeit pro Workflow, manuelle Eingriffe pro Task, Fehlerquote, echte Zeitersparnis im Team.
Ein pragmatischer Startpunkt für Teams
- Starte mit 1–2 eng begrenzten MCP-Use-Cases (hoher Nutzen, überschaubares Risiko).
- Baue eine kleine interne Allowlist statt „alles offen“.
- Dokumentiere jeden Server wie eine produktive API-Komponente (Owner, Version, Scope, SLA).
- Miss von Tag 1 an Wirkung, nicht nur technische Machbarkeit.
So verhinderst du den häufigsten Fehler: früh zu breit gehen und dann im Betrieb die Kontrolle verlieren.
Ausblick auf Teil 2 und Teil 3
- Teil 2: Produktionsarchitektur im Detail (Registry, Domain-Server, Security-Layer, Review-Gates).
- Teil 3: Rollout-Playbook (Teamreihenfolge, Metriken, typische Fallstricke und wie man sie früh erkennt).
Quellen (für Fact-Check)
- Linux Foundation – AAIF Event-Programm
- MCP Dev Summit – Programm/Livestream
- InfoQ – Pinterest MCP Ecosystem
Mehr aktuelle Updates: LLM News
Startpunkt: Artikel-Hub
Leave a Reply