Category: LLM News
-
Serie LLM Ops Stack (Teil 2): Observability, Fallbacks und Kostenkontrolle
Serie: LLMs produktiv betreiben (Teil 2 von 2) Serien-Navigation: Teil 1 · Teil 2 Im zweiten Teil geht es um die Realität nach dem Go-live: inkonsistente Antwortqualität, Spitzenlast, …
Written by

-
LiteLLM-Vorfall zeigt die neue Angriffsfläche für Agentic Ops
Wenn ein AI-Gateway wie LiteLLM in der Lieferkette getroffen wird, ist das nicht nur ein Security-Thema – das ist ein Betriebsrisiko für jedes Team mit Agenten, Automationen oder …
Written by

-
Local vs Cloud Check (Teil 2): Kosten, Latenz und der reale Break-even
Serien-Navigation · Local vs Cloud Check Teil 1 · Teil 2 · Teil 3 Serie: Local vs Cloud Check (Teil 2 von 3) Teil 2 vertieft Kosten-, Latenz- …
Written by

-
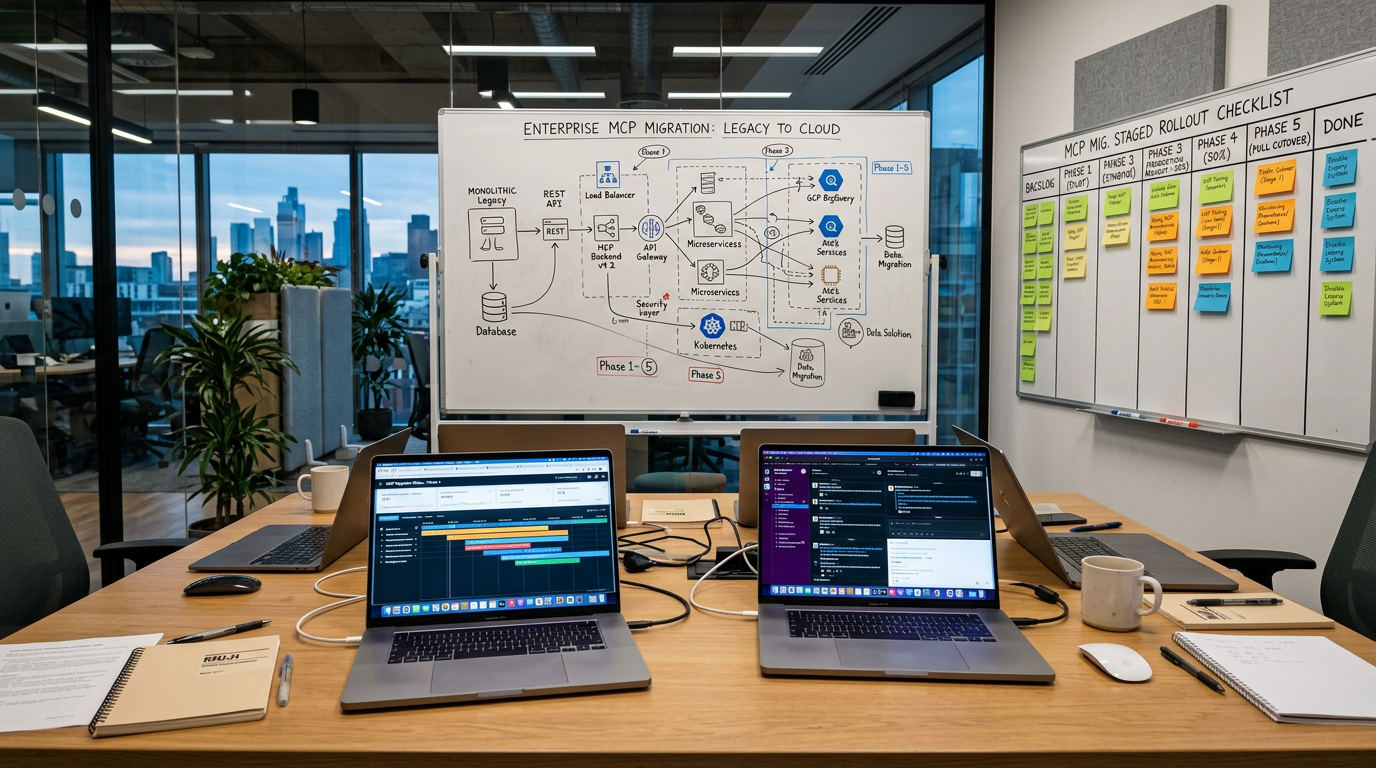
Serie MCP im Enterprise (Teil 1): Vom Agenten-Hype zur Infrastruktur
Serien-Navigation · MCP im Enterprise Teil 1 (aktuell) · Teil 2 (in Arbeit) · Teil 3 (in Arbeit) Zur Serienübersicht → Serie: MCP im Enterprise-Betrieb (Teil 1 von …
Written by
-
Microsoft veröffentlicht Agent Governance Toolkit für autonome AI-Agenten
Autonome Agenten können heute nicht nur chatten, sondern reale Aktionen auslösen: Tools aufrufen, Workflows starten, Infrastruktur anfassen. Genau dort liegt das Risiko – und genau dort setzt Microsofts …
Written by

-
MLPerf Inference v6.0 zeigt, wo Inference-Stacks jetzt wirklich gewinnen
Inference-Benchmarks sind nicht sexy — aber sie entscheiden gerade, welche AI-Stacks in Produktion bestehen. Mit MLPerf Inference v6.0 hat MLCommons diese Woche die bislang größte Überarbeitung der Suite …
Written by

-
Gemma 4 macht Local-First plötzlich enterprise-tauglich
Google hat mit Gemma 4 ein Update veröffentlicht, das für Teams mit Local-/Edge-Fokus mehr ist als nur ein Modell-Refresh. Der eigentliche Hebel ist die Kombination aus zwei Dingen: …
Written by

-
Inference wird zum Betriebssystem: Dynamo, 1M-Context-Shift, Runtime-Routing
Die letzten Tage zeigen ein klares Muster: Der LLM-Markt liefert weniger „Big Bang“-Modelle, dafür deutlich mehr produktionsnahe Infrastruktur und Runtime-Änderungen. Für Teams heißt das: weniger Hype-Slides, mehr Betriebsdisziplin. …
Written by

-
Serie LLM Ops Stack (Teil 1): Basis für produktiven Betrieb
Stand: April 2026 In den letzten Monaten habe ich viel damit gearbeitet, lokale LLMs von „läuft auf meinem Rechner“ auf „läuft stabil im Alltag“ zu bringen. Der Unterschied…
Written by

-
Homelab Setup: Docker + Monitoring in 60 Minuten
Docker und Monitoring in unter einer Stunde ist realistisch, wenn das Setup klar bleibt. Der Artikel zeigt ein schlankes Homelab-Grundgerüst mit Fokus auf Wartbarkeit statt Tool-Overkill.
Written by
